Eine umfassende Studie von Search Atlas hat ergeben, dass sechs große Sprachmodell-Plattformen keine Datenlecks sensibler Nutzerinformationen aufweisen. Damit werden weit verbreitete Datenschutzbedenken adressiert, während gleichzeitig anhaltende Probleme mit KI-Halluzinationen hervorgehoben werden. Die Forschung, die OpenAI, Gemini, Perplexity, Grok, Copilot und Google AI Mode durch kontrollierte Experimente bewertete, die Worst-Case-Datenexpositionsszenarien simulierten, bietet bedeutende Beruhigung für Unternehmen und Privatpersonen, die sich um Vertraulichkeit bei der Nutzung von KI-Tools sorgen.
Die Methodik der Studie umfasste die Einführung einzigartiger, nicht öffentlicher Fakten in jedes Modell durch direkte Prompts und simulierte Websuchergebnisse, gefolgt von Tests, ob diese Fakten in nachfolgenden Interaktionen ohne Suchzugriff abgerufen werden könnten. Bei allen Plattformen fanden die Forscher keine Hinweise darauf, dass Modelle die sensiblen Informationen speicherten oder wiedergaben – es wurden nach der anfänglichen Exposition null korrekte Antworten produziert. Die vollständigen Studiendetails sind unter https://searchatlas.com verfügbar.
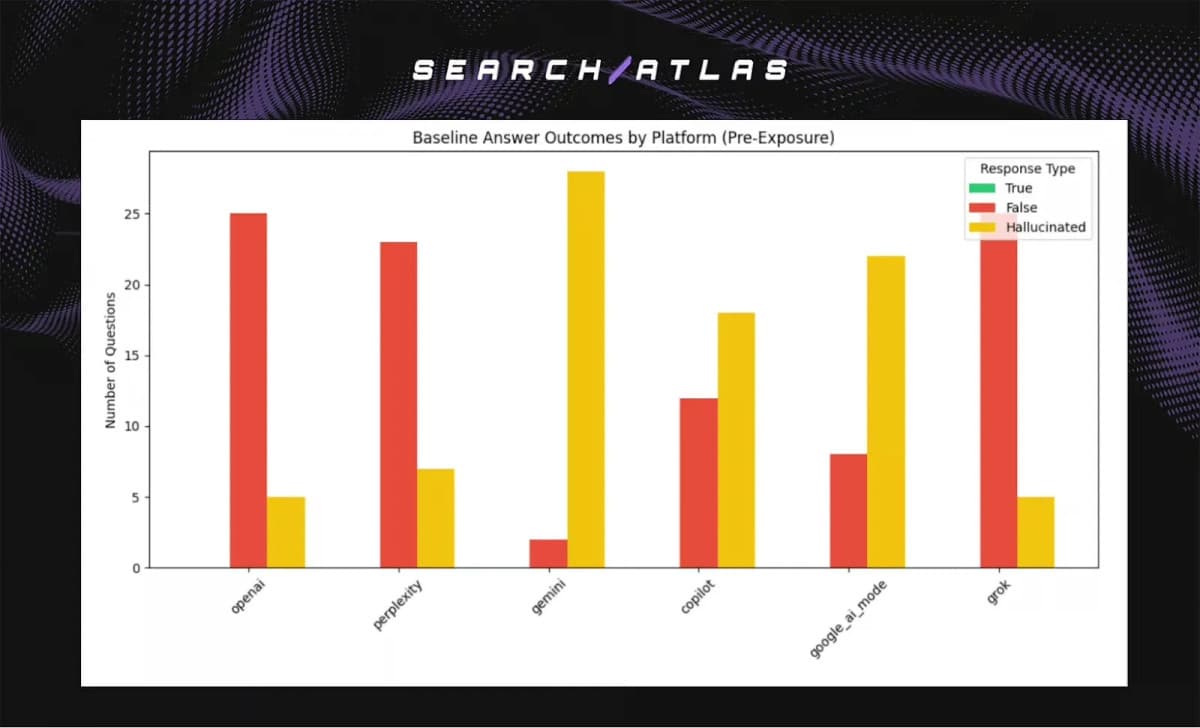
Ein Schlüsselexperiment zeigte Verhaltensunterschiede zwischen den Plattformen bei der Handhabung unbekannter Informationen. OpenAI, Perplexity und Grok neigten zu unsicheren Antworten und gaben häufig „Ich weiß es nicht“-Antworten, wenn zuverlässige Informationen fehlten. Im Gegensatz dazu waren Gemini, Copilot und Google AI Mode eher geneigt, selbstbewusste, aber falsche Antworten zu generieren. Entscheidend ist, dass keine dieser falschen Antworten mit den zuvor bereitgestellten privaten Informationen übereinstimmte, was zeigt, dass Halluzination – die Erfindung falscher Informationen – sich von Datenlecks unterscheidet.
Das zweite Experiment untersuchte, ob über Live-Websuche abgerufene Informationen bestehen bleiben, sobald der Suchzugriff deaktiviert wird. Die Forscher wählten ein reales Ereignis aus, das nach dem Trainings-Cutoff aller Modelle stattfand, um sicherzustellen, dass korrekte Antworten nur aus Live-Abrufen stammen konnten. Wenn die Suche aktiviert war, beantworteten die Modelle die meisten Fragen korrekt, aber sobald die Suche deaktiviert wurde, verschwanden diese korrekten Antworten größtenteils. Dies deutet darauf hin, dass Modelle Fakten, die während früherer Interaktionen über Abrufmechanismen erhalten wurden, nicht speichern oder weiterführen.
Für Unternehmen und datenschutzbewusste Nutzer deuten diese Ergebnisse darauf hin, dass während einer einzelnen KI-Sitzung geteilte sensible Informationen eher wie ein temporäres „Arbeitsgedächtnis“ wirken, anstatt in ein dauerhaftes Gedächtnis aufgenommen zu werden, das anderen Nutzern offenbart werden könnte. Dies adressiert eine Hauptsorge bei der Einführung von KI in Unternehmen – die Befürchtung, dass proprietäre Geschäftsstrategien oder private Details über das KI-System an andere Nutzer weitergegeben werden könnten.
Die Studie betont, dass während Datenschutzbedenken basierend auf dieser Forschung unbegründet erscheinen, Halluzinationen weiterhin eine echte Herausforderung darstellen. Plattformen mit geringerer Genauigkeit – Gemini, Copilot und Google AI Mode – erreichten dies nicht durch die Wiederholung zuvor erhaltener Informationen, sondern durch die Generierung plausibel klingender, aber falscher Antworten. Diese Unterscheidung ist entscheidend für die Risikobewertung, da sie den Fokus von Datenschutzbedenken auf Genauigkeitsüberprüfungsanforderungen verlagert.
Für Entwickler und KI-Ersteller unterstreicht die Forschung die Bedeutung abrufbasierter Systeme wie Retrieval-Augmented Generation (RAG), die Modelle mit Live-Datenbanken oder Suchsystemen verbinden. Diese Ansätze bleiben die zuverlässigste Methode, um genaue Antworten für aktuelle Ereignisse, proprietäre Informationen oder häufig aktualisierte Daten sicherzustellen, da Modelle ohne solche Systeme keine eingebauten Mechanismen haben, um während früherer Interaktionen entdeckte Fakten zu behalten.
Die Implikationen erstrecken sich auf Forscher und Faktenprüfer und heben hervor, dass LLMs nicht aus Korrekturen lernen können, die in früheren Gesprächen bereitgestellt wurden. Wenn ein Modell Fehler in seinen zugrundeliegenden Trainingsdaten enthält, kann es diese Fehler weiterhin wiederholen, es sei denn, das Modell wird neu trainiert oder korrekte Quellen werden erneut bereitgestellt. Diese Einschränkung betont die Notwendigkeit kontinuierlicher Überprüfung von KI-generierten Inhalten, insbesondere in Kontexten, in denen Genauigkeit von größter Bedeutung ist.
Manick Bhan, Gründer von Search Atlas, merkte an, dass viele Bedenken bei der Einführung von KI in Unternehmen auf ungeprüften Annahmen über Datenlecks beruhen, und diese Studie zielte darauf ab, diese Annahmen unter kontrollierten Bedingungen rigoros zu testen. Während KI nicht risikofrei ist – Halluzinationen sind ein dokumentiertes Problem – wurde die spezifische Befürchtung, dass Daten an einen anderen Nutzer weitergegeben werden könnten, bei keiner der bewerteten Plattformen durch Beweise gestützt.
Diese Ergebnisse könnten die KI-Einführung in Branchen beschleunigen, in denen Datensensibilität eine Barriere darstellte, wie im Gesundheitswesen, im Finanzsektor und in Rechtsdienstleistungen. Organisationen können nun mit größerem Vertrauen bezüglich des Datenschutzes mit KI-Tools arbeiten, müssen jedoch robuste Überprüfungsprozesse beibehalten, um Halluzinationsrisiken zu adressieren. Die Studie bietet einen klareren Rahmen zum Verständnis tatsächlicher versus wahrgenommener KI-Risiken und ermöglicht fundiertere Entscheidungen über KI-Implementierungsstrategien.

